Create a Bruin Project
Initialize a Bruin project - the local workspace that will hold your database metadata, quality checks, and agent context.
What you'll do
Create an empty Bruin project using the CLI. This gives you the folder structure and config file that every other step builds on.
Why this step matters
Before an AI agent can analyze your data, it needs somewhere to store the knowledge it will work with - table schemas, column descriptions, quality checks, and domain context. A Bruin project is that workspace. It's a plain folder on your machine with a small config file (.bruin.yml) and one or more asset directories that describe your data.
Think of it like a README for your database, but machine-readable. Without this structure, the AI agent would be flying blind - guessing table names, inventing column meanings, and writing queries that may not even run. The project gives it ground truth.
If you already have a Bruin project, skip ahead to Step 2: Connect Your Data.
Video walkthrough
If you prefer video, this core concept walkthrough covers project initialization end-to-end:
Instructions
Bruin projects must live inside a git repository - that's how Bruin tracks changes and ensures your data context is version-controlled. If your current folder is already a git repo, bruin init will create the project right inside it. If it's not, Bruin will automatically run git init for you, so you don't need to do it manually.
Open your terminal and run:
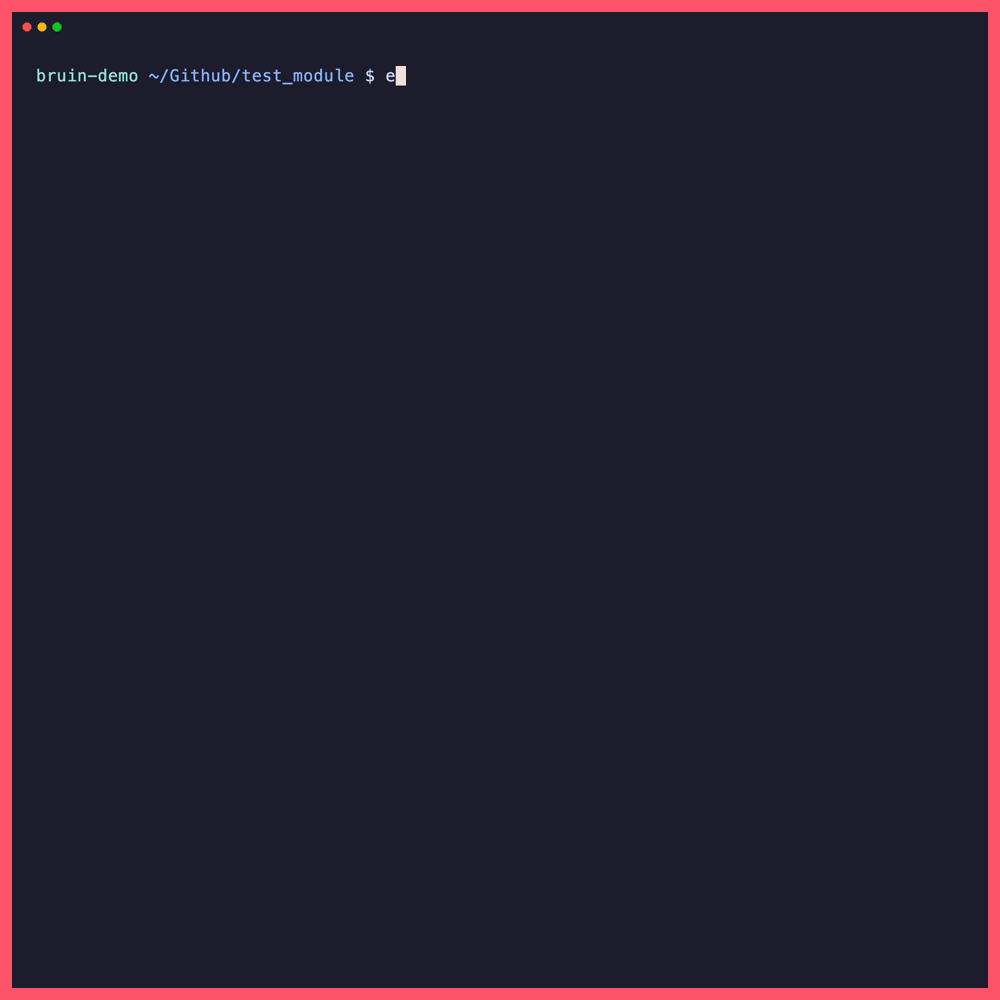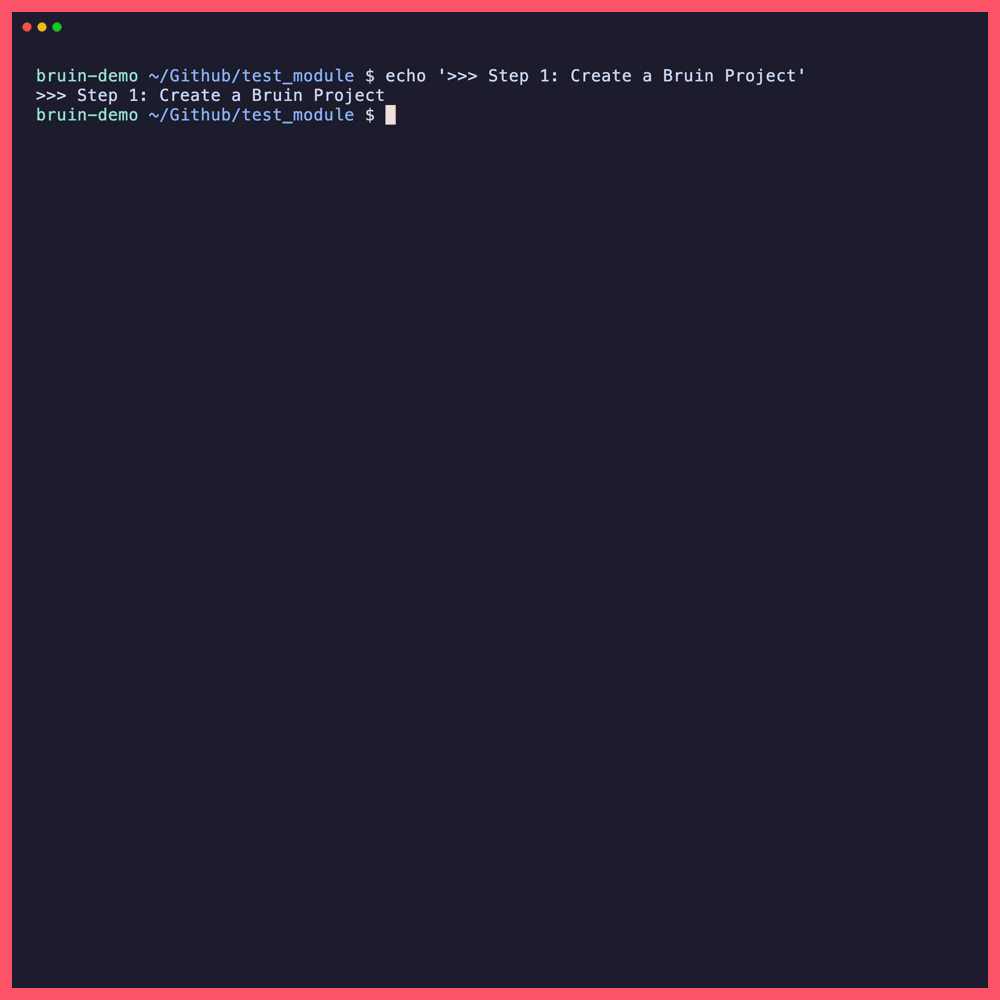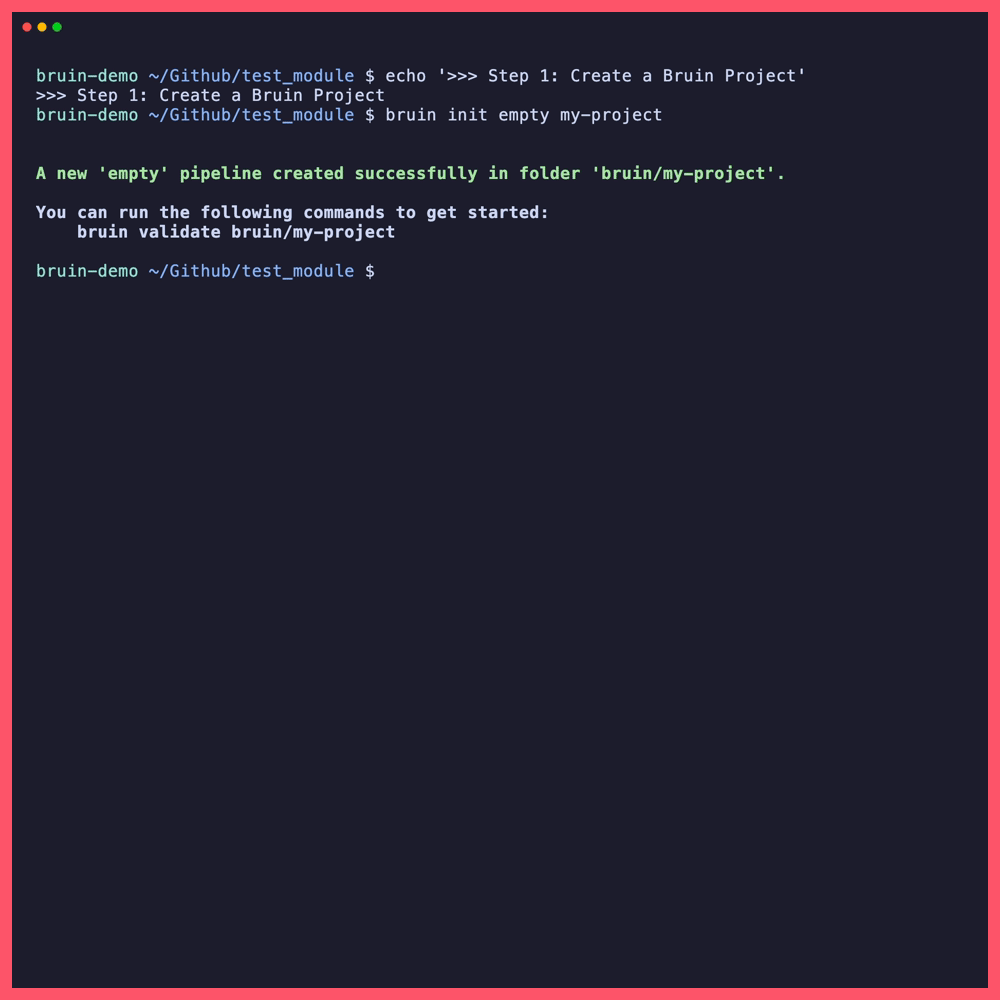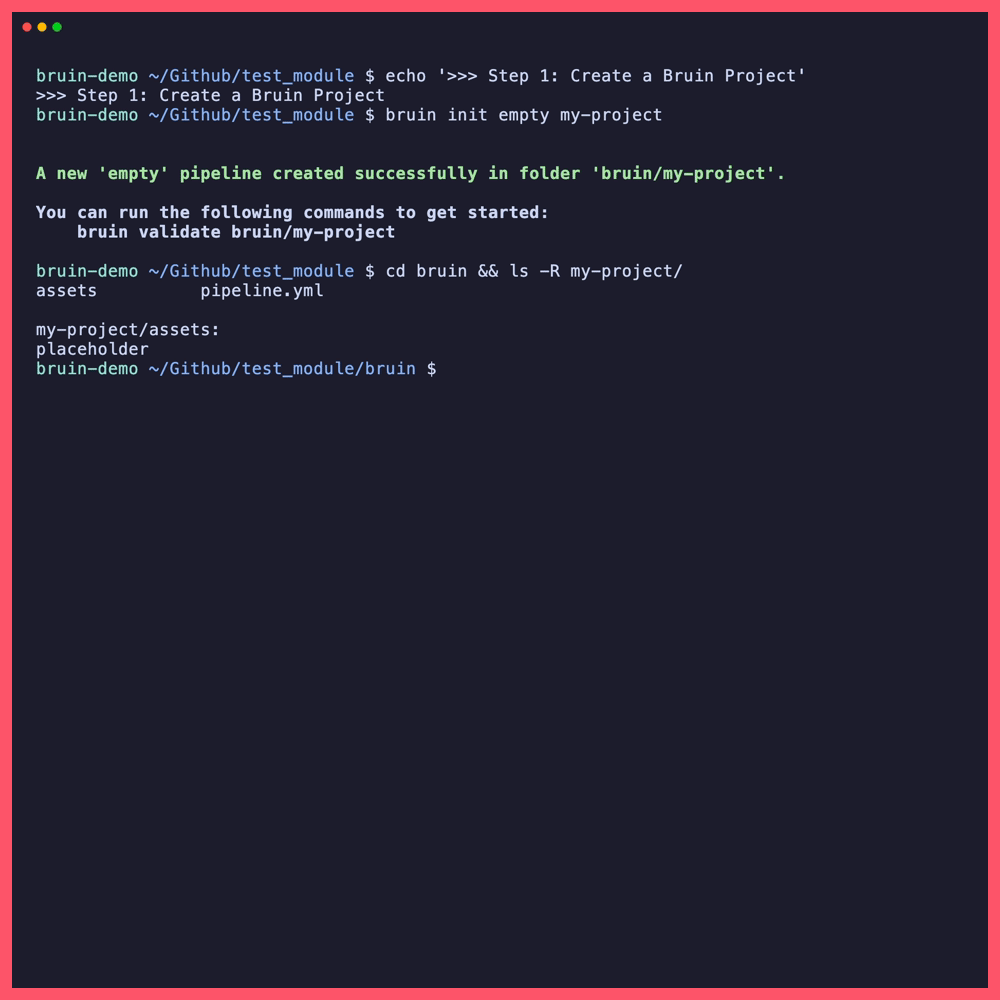
bruin init empty my-project
This creates a .bruin.yml config file at your git repo root and a pipeline folder called my-project/. Rename the pipeline folder to ai-analyst so it doesn't get confused with the project name:
mv my-project ai-analyst
What gets created
The result depends on whether your current directory was already a git repository:
If you're already in a git repo:
./ # your repo root IS the project root
├── .bruin.yml # project config - connections, environments
└── ai-analyst/ # pipeline folder (renamed from my-project)
├── pipeline.yml # pipeline config - name, schedule, defaults
└── assets/ # where your table definitions will live
Bruin places .bruin.yml at the repo root and creates the pipeline folder next to it.
If you're NOT in a git repo:
bruin/ # project root (Bruin creates this + runs git init)
├── .bruin.yml # project config
└── ai-analyst/ # pipeline folder (renamed from my-project)
├── pipeline.yml
└── assets/
Bruin creates a bruin/ folder, runs git init inside it, and places everything there. Run cd bruin first, then rename the pipeline folder.
Verify your setup
From the project root (the directory containing .bruin.yml), confirm your project structure:
ls -la
You should see .bruin.yml and the ai-analyst/ folder in this directory. This is your Bruin project root - the directory you'll work from in all subsequent commands.
Push to GitHub
Your Bruin project folder is a full git repository - it was either created inside an existing one or Bruin ran git init for you. This means you can push it to GitHub (or any other git remote) just like any codebase:
git add .
git commit -m "initial bruin project"
git remote add origin https://github.com/your-org/your-repo.git
git push -u origin main
This gives you version control over your entire data context: table schemas, column descriptions, quality checks, and pipeline definitions all live in git. Your team can review changes in pull requests, roll back mistakes, and keep a clear history of how your data knowledge evolves over time.
You can also create the repository on GitHub first and clone it before running
bruin init- either workflow works.
What just happened
You now have a local Bruin project with a .bruin.yml config file ready to accept database connections and an assets folder waiting for table definitions. The project lives inside a git repository, so you can push it to GitHub and collaborate with your team from day one - your entire data context is version-controlled alongside your code.